A
Ankit Kumar BaralPublished on April 15, 2026
17 min read
RAG Architecture Explained: Unveiling Retrieval Augmented Generation
Discover the foundational components and transformative use cases of RAG AI.

Discover the foundational components and transformative use cases of RAG AI.
Header image depicting the concept of RAG in modern, geometric style.
In the ever-evolving landscape of Artificial Intelligence (AI), one of the most innovative technologies is Retrieval Augmented Generation (RAG). This blog focuses on rag architecture explained, exploring its essential components and significance within the field.
Retrieval Augmented Generation represents a sophisticated interplay between retrieval models and sequence-to-sequence (seq2seq) models. But what does RAG contribute to AI? It introduces a distinctive approach to contextual dialogue by generating nuanced responses grounded in the information it retrieves.
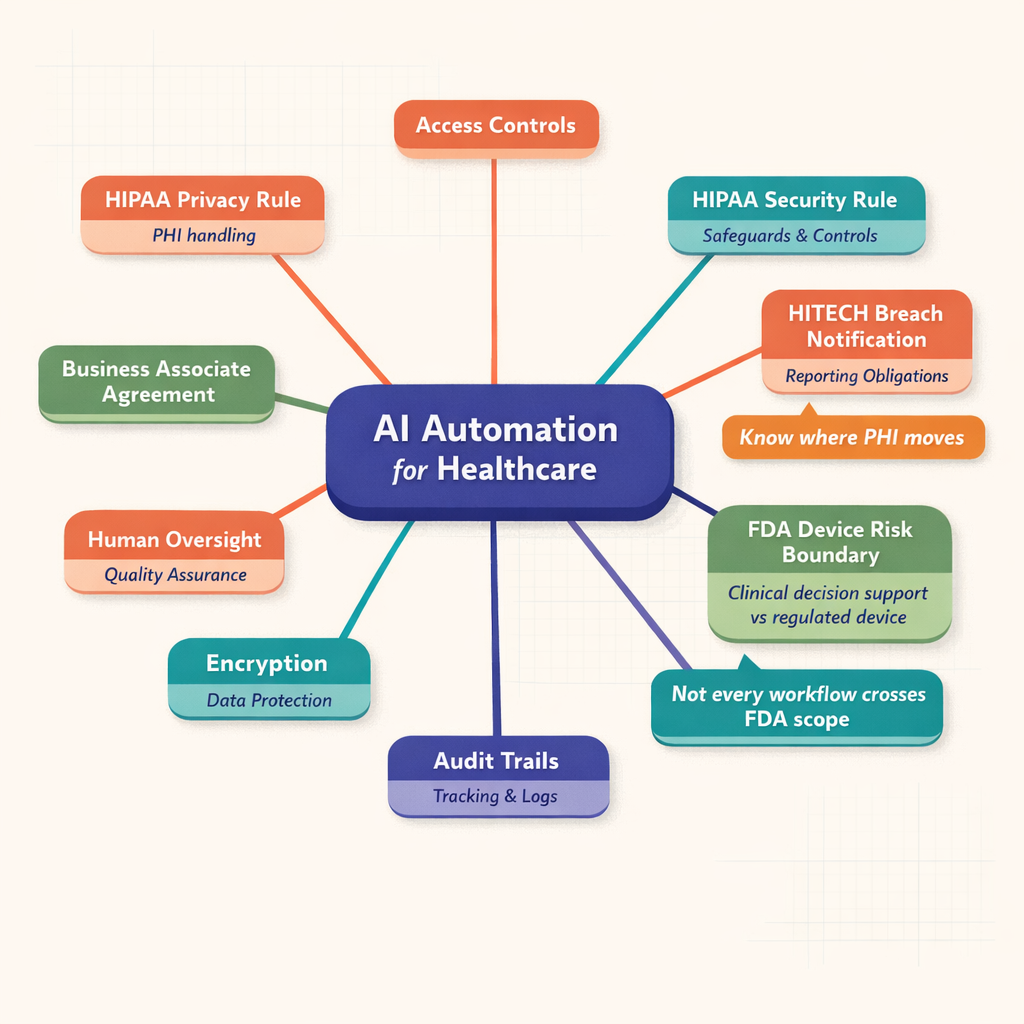
The RAG system architecture is notable for its capacity to manage vast datasets while producing responses with remarkable expressiveness. This capability is facilitated through a complex, multi-stage process, which we will examine more closely in the sections to follow. The stages involved include:
The expansive potential of RAG goes well beyond current applications. RAG use cases encompass a variety of scenarios, ranging from basic Q&A systems to intricate content creation tasks. We will explore compelling examples that showcase RAG's capabilities and its promising implications for the future of AI.
Additionally, we will investigate advanced patterns associated with RAG, consider potential failure modes, and conclude with a section addressing frequently asked questions to clarify key aspects of RAG.
In conclusion, this blog seeks to comprehensively explain the RAG architecture, demystify what is RAG AI, and examine its engaging use cases. By the end of this discussion, the complexities surrounding RAG should feel more accessible and intriguing. We aim to stimulate your curiosity and provide an enlightening journey into the realm of Retrieval Augmented Generation.
: RAG Explained: Architecture and Use Cases
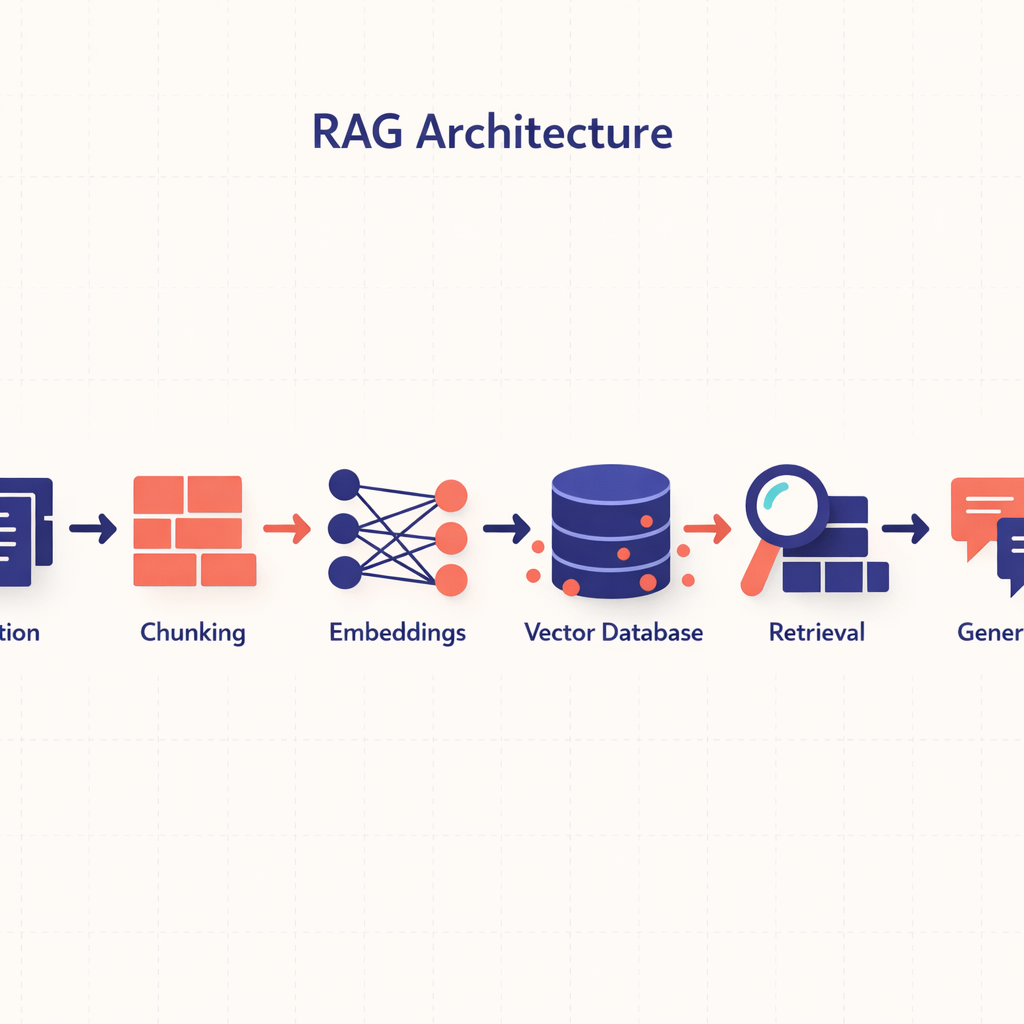 Diagram of RAG architecture.
Diagram of RAG architecture.
Retrieval Augmented Generation, or RAG, is an innovative approach in the field of AI aimed at delivering a robust and context-aware conversational experience. So, when we ask, what is RAG AI? It is an advanced system architecture that bridges the gap between retrieving extensive knowledge and generating sophisticated responses.
To comprehend this, let’s break down how the RAG system architecture functions.
The process begins with data ingestion. In this phase, data is deconstructed into smaller units, making it easier for the AI to process. In simpler terms, it resembles preparing bite-sized pieces of knowledge for consumption.
Next, we have chunking. During this stage, the ingested data is divided into manageable chunks that are suitable for AI analysis.
A crucial process within RAG is the creation of embeddings. These are vector representations of the chunks that capture semantic information effectively.
These embeddings are stored in systems known as Vector Databases. These databases function as bridges, transforming raw data into usable insights and are essential for the retrieval phase of RAG.
The retrieval phase involves sourcing the most appropriate data from the database by comparing embeddings. This is the stage where RAG accesses its previously stored knowledge bank.
The final phase of the RAG system architecture is generation. Here, RAG utilizes a seq2seq generator to convert the retrieved information into coherent and contextually accurate responses.
Maintaining a consistent supply of data to the language models is essential for the successful operation of RAG. The system relies on a rich database to retrieve and generate knowledgeable, relevant responses. Without these data banks, RAG would lack the foundational basis for its operations.
RAG represents a promising system with significant potential for complex, real-world applications. Its state-of-the-art architecture paves the way for a new realm of possibilities in the world of AI.
In our exploration of retrieval augmented generation (RAG), we delve deeper into the key architectural stages: ingestion, chunking, embeddings, vector databases, retrieval, and finally, generation. Each stage plays a fundamental role in realizing RAG's full potential, and we aim to illuminate the pivotal contribution of each phase.
The RAG system architecture begins with data ingestion, a critical stage where raw data is broken down into smaller, manageable units. This phase is essential, as it ensures that the AI can effectively process large volumes of data without compromising accuracy or efficiency.
Following ingestion, the data progresses to the second stage—chunking. Here, the ingested data is further divided into 'chunks' that the AI can efficiently process. The objective is to simplify operations, reducing compute time and significantly enhancing overall system performance.
In the embeddings stage, each chunk is converted into vector representations, known as "embeddings," which capture the semantic properties of the chunks. This process is crucial for extracting context from raw data, enabling the AI to understand and compare different chunks.
The next step involves vector databases, also referred to as indexing. These embeddings are stored in vector databases, which serve as the bridge between raw data and usable information, thereby facilitating straightforward data retrieval.
During the retrieval phase, the RAG system utilizes the embeddings to fetch relevant information from the vector database. The system is designed to access a database containing billions of documents, locating the most pertinent entries based on the given embeddings.
Finally, in the generation stage, the RAG system employs a sequence-to-sequence generator to transform the retrieved documents into human-like responses. This phase ensures that the generated responses are not only coherent but also contextually relevant and nuanced.
Understanding the RAG architecture provides valuable insights into the impressive capabilities of modern AI technologies. Furthermore, it opens up a world of possibilities for extending and fine-tuning these technologies to meet specific application requirements, a topic we will explore in subsequent discussions.
Retrieval Augmented Generation (RAG), fine-tuning, and prompting are distinct approaches within the realm of Language Learning Models (LLMs). Each method possesses unique characteristics, benefits, and limitations. To gain a comprehensive understanding of these technologies, let us explore each approach, starting with an introduction to RAG AI.
In artificial intelligence, Retrieval Augmented Generation (RAG) represents an innovative model that integrates the advantages of retriever models and sequence-to-sequence (seq2seq) models. The RAG AI system encompasses several key stages: ingestion, chunking, embeddings, vector databases, retrieval, and generation. The essence of the RAG architecture lies in its ability to dynamically retrieve and generate responses based on contextual information, facilitating nuanced and contextually relevant conversations.
Fine-tuning is a transfer learning technique whereby a pre-trained model undergoes further training on a specific, often smaller, task. This method allows the model to leverage the extensive knowledge acquired during pre-training and apply it to targeted tasks. However, a significant limitation of fine-tuning is that the model’s knowledge can become outdated if it is not periodically retrained or updated with new data.
Prompting is another technique employed in LLMs, which involves providing specific instructions or prompts to guide the model in producing the desired output. While prompting can yield dynamic and versatile performance, its effectiveness is heavily contingent upon the ability to craft precise and well-defined prompts.
Now that we have elucidated the RAG architecture and examined the characteristics of fine-tuning and prompting, we can make some comparisons.
| Approach | Strengths | Limitations |
|---|---|---|
| RAG | Excels in question answering and fact-checking tasks, capable of scanning billions of documents to retrieve contextually relevant information. | |
| Fine-tuning | Performs effectively in tasks requiring domain-specific expertise. | Performance may degrade over time without retraining or incorporating fresh data. |
| Prompting | Highly effective in applications where prompts can be easily crafted or formulated. | Effectiveness is directly related to the quality of the prompts. |
 Comparative image of RAG, fine-tuning, and prompting.
Comparative image of RAG, fine-tuning, and prompting.
A comprehensive understanding of retrieval augmented generation, or RAG, is incomplete without examining its practical applications. Below, we explore notable RAG use cases that exemplify its efficiency and versatility across a range of complex problem-solving scenarios.
Leveraging the robust RAG architecture, chatbots and digital assistants can achieve unprecedented performance in understanding and addressing user queries. They are capable of sifting through vast volumes of data, identifying relevant information, and crafting nuanced responses — all in real time. This marks a significant improvement over traditional systems, greatly enhancing the user experience.
Another critical use case for RAG AI is data-driven decision making. By analyzing substantial amounts of heterogeneous data, retrieval augmented generation can extract valuable insights, thus supporting informed decision-making processes. It excels in scenarios that require a profound understanding of raw data, identifying patterns, and generating contextual analysis — attributes that are essential for:
RAG's proficiency in text generation can also be harnessed for producing high-quality content — ranging from news articles and summaries to personalized marketing copy. It can select the most relevant information from a multitude of sources, organizing it into coherent and contextually appropriate content.
The RAG system architecture, with its capability for understanding and generating language, can be effectively applied to translation and localization tasks. It demonstrates high performance in interpreting and reproducing the semantic and syntactic structures of different languages, resulting in accurate translations.
The essence of these RAG use cases lies in the system's ability to leverage its vast knowledge database and generate intelligent responses, regardless of the context or domain.
As advancements in AI continue to unfold, the potential of RAG is set for further exploration, promising exciting developments that enrich our everyday digital interactions. The power of RAG resides in its ability to transform raw data into meaningful insights, heralding a significant leap forward in AI capabilities.
As AI enthusiasts, let us delve deeper into the remarkable technology of Retrieval Augmented Generation (RAG) by exploring some advanced patterns that emerge when leveraging its potential.
One groundbreaking pattern in the RAG system architecture is the ability to utilize contextual cues to modify the scope of retrieval. What does this entail? In traditional methods, AI relies on predefined documents or sources to generate responses. However, with RAG, AI can dynamically adjust the retrieval field based on the context of the conversation.
Another key feature is the iterative refinement of responses. This iterative nature, present in some advanced RAG implementations, enables the model to retrieve, generate, reassess, and revise its outputs, significantly enhancing response quality over multiple iterations.
Moreover, the substantial size and diversity of the document set utilized in RAG lead to patterns of nuance and precision. A larger, varied document set allows for better customization of responses, thereby improving the performance of AI in specialized contexts.
In summary, the advanced patterns exhibited by the RAG system architecture enhance its capacity to address diverse and complex demands, ultimately providing a superior AI experience.
The next time you observe an AI assistant delivering remarkably relevant responses or a fact-checking system adeptly dismantling misinformation, remember: you are likely witnessing the advanced patterns of RAG in action. For developers and AI enthusiasts, understanding these patterns can empower you to utilize RAG more effectively in your projects.
References will be provided at the end of this article.
Understanding how to identify potential pitfalls in the retrieval augmented generation (RAG) model is essential for optimizing system performance. In this section, we will examine common failure modes within the RAG system architecture and explore strategies to mitigate them.
One significant issue can arise from the selectivity of the system. This characteristic poses a double-edged sword for RAG. On one hand, it delivers contextually relevant responses by retrieving the best-fit documents from a vast databank. On the other hand, an over-reliance on retriever selectivity may lead to the omission of valuable information.
RAG's strength lies in its ability to outperform traditional literal match-based retrieval. However, the model may sometimes place excessive emphasis on syntactic similarity, resulting in responses that lack semantic relevance.
Despite RAG's capability to retrieve multiple documents, it may concentrate heavily on only a subset of these during the generation process.
Ultimately, while these common challenges may arise, they are not inherently detrimental to the RAG model. Rather, they present opportunities that, when addressed effectively, enable us to leverage these models to their full potential.
As part of our "RAG Explained: Architecture and Use Cases” series, we address some frequently asked questions. This section aims to enhance your understanding of Retrieval-Augmented Generation (RAG), clarify what RAG AI is, and provide deeper insights into RAG system architecture.
RAG distinguishes itself from traditional models through its hybrid architecture, which integrates two sophisticated AI techniques: retrieval-based models and seq2seq models. Unlike conventional models that rely exclusively on pre-defined documents or sources for content generation, RAG employs a unique, multi-stage process. This process includes data ingestion, chunking, vector embeddings, retrieval, and finally, generation. The outcome is a significant enhancement in the relevance and expressiveness of the generated responses, yielding more accurate and contextually rich results.
Given RAG's architecture, it excels in applications that require nuanced, contextually relevant responses. Common use cases include:
RAG's primary value lies in its ability to swiftly process vast quantities of data and deliver relevant output, making it ideal for any AI application that involves searching extensive databases to generate coherent responses.
Although RAG offers significant benefits, it is crucial to acknowledge its limitations. One common challenge is its selectivity; while designed to extract the most relevant documents from vast databases, it may occasionally prioritize a few phrases at the expense of broader context. Furthermore, managing large vector databases demands substantial computational power, which can pose difficulties for less-equipped systems.
In summary, RAG represents a remarkable advancement in AI's capacity to generate meaningful, context-aware responses. It embodies the evolving possibilities within the AI field, transforming how we approach data retrieval and content generation.
 Final image summarizing the significance of RAG.
Final image summarizing the significance of RAG.
As we conclude our in-depth exploration of the mechanics behind Retrieval Augmented Generation (RAG), it is crucial to recognize the transformative impact of this technology. Understanding "rag architecture" provides significant insights into the latest innovations in AI, paving the way for broader learning and experimentation.
At its core, retrieval augmented generation combines the strengths of retrieval-based models and sequence-to-sequence models, creating an AI system capable of engaging in contextual and nuanced conversations. The stages that define the RAG system architecture—ranging from data ingestion to content generation—illustrate how the model interacts with information, processes it semantically, and produces human-like responses.
Here are the key takeaways:
| Stage | Description |
|---|---|
| Ingestion and Chunking | This stage involves breaking down large volumes of data into manageable segments, facilitating efficient AI processing. |
| Embeddings and Vector Databases | Semantic properties encode the significance of raw data segments. These properties are stored in vector databases, forming a comprehensive repository of usable information. |
| Retrieval and Generation | The AI utilizes semantic embeddings to retrieve contextually relevant information. After retrieval, it leverages a sequence-to-sequence generator to formulate responses that align with the context. |
RAG's advanced architecture significantly alters how AI models understand and communicate, distinguishing it from traditional models. Notably, it overcomes the limitations of fine-tuning and prompting, adopting a more flexible and context-aware approach.
However, RAG is not without its flaws. Like any technical solution, it has its failure modes. Understanding these pitfalls will help users optimize their use of RAG models and establish realistic expectations.
Reflecting on "what is rag ai," we witness the ongoing evolution of AI technology, pushing the boundaries of machine comprehension and human interaction. We encourage all curious minds to delve deeper into RAG's intriguing integration of information retrieval and generative sequencing. Ultimately, the journey toward AI innovation is fueled by continuous learning and practical experimentation.
Now that you have a solid understanding of RAG's workings, it's your turn to explore, experiment, and contribute to the advancement of this groundbreaking technology.