N
Naresh HRPublished on April 15, 2026
17 min read
RAG vs Fine-Tuning: Choosing the Right AI Customization Strategy
Discover when to use RAG vs fine-tuning for optimal AI performance.

Discover when to use RAG vs fine-tuning for optimal AI performance.
Hero image with abstract representation of RAG and Fine-Tuning
In the rapidly evolving field of Artificial Intelligence (AI), customization is crucial for enhancing the effectiveness and applicability of Language Learning Models (LLMs). The flexible nature of AI enables engineers to adjust a model's functionality, ensuring optimal solutions for specific tasks. Given the wide range of applications for these models, the significance of customization cannot be understated. This brings us to two prominent strategies for customizing LLMs: Retrieval-Augmented Generation (RAG) and Fine-Tuning. The focus of this blog post is to provide a detailed comparison of these two approaches.
RAG represents an innovative integration of extractive question-answering and generative language models. In essence, RAG empowers a model to generate responses by retrieving relevant documents from an extensive repository. This approach enhances the diversity and contextual relevance of the outputs. By leveraging the scaling capabilities of pre-trained models like Transformers, RAG effectively manages large data volumes while delivering rich, nuanced responses.
Conversely, Fine-Tuning adopts a more straightforward approach, where the parameters of an already trained model are modified to better meet the demands of a specific task. This adaptability, combined with its inherent simplicity, allows Fine-Tuning to quickly customize pre-trained models, thereby saving both time and computational resources. A notable advantage of Fine-Tuning is its enhanced generalization capabilities, which arise from learning from large-scale datasets.
When examining the "RAG vs Fine-Tuning" debate, several factors come into play. The table below summarizes the key distinctions:
| Feature | RAG | Fine-Tuning |
|---|---|---|
| Complexity | Higher, due to the two-step document retrieval and synthesis | Lower, due to straightforward parameter adjustment |
| Latency | Generally higher, resulting from retrieval dependency | Typically lower, enabling faster predictions |
| Cost | Can incur higher costs associated with document retrieval | Lower costs, thanks to a streamlined approach |
| Generalization | Varies based on the retrieved documents | Enhanced, owing to extensive training data |
In this blog post, we will explore these methods in greater detail, providing you with a robust decision-making framework. We will also investigate the potential of hybrid models and present practical examples. Stay tuned for further insights, comparisons, and FAQs as we delve more deeply into the fascinating world of LLM customization.
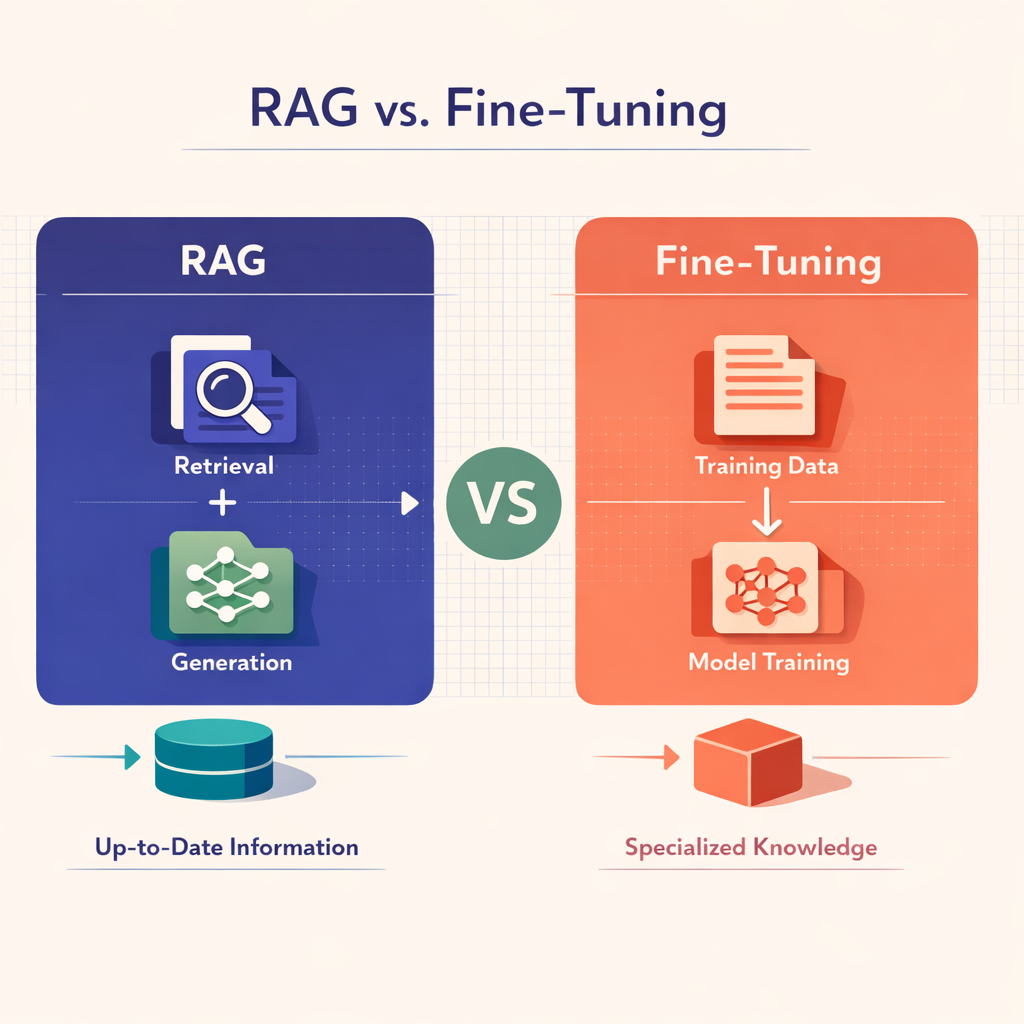 Comparative diagram of RAG vs Fine-Tuning
Comparative diagram of RAG vs Fine-Tuning
Retrieval Augmented Generation (RAG) represents one of the most innovative approaches for customizing Language Learning Models (LLMs) in artificial intelligence. It serves as a powerful alternative to the commonly employed practice of fine-tuning AI models, featuring key differences in methodology and outcomes that are designed to support diverse and context-sensitive functionalities.
RAG effectively integrates two fundamental tasks: extractive question answering and generative language modeling. This combination enables an intelligent system in which the model, when presented with a query or prompt, navigates through a vast corpus of documents to extract pertinent information. This document retrieval is subsequently followed by a synthesis process, allowing the model to generate coherent and relevant responses.
The process can be likened to rapidly traversing an extensive library, selecting relevant books, and then crafting a comprehensive answer based on the accumulated knowledge. This distinctive nature bestows RAG-based models with a competitive advantage in delivering detailed and contextually nuanced data in their responses.
Although RAG is more complex than traditional fine-tuning methods, it offers several significant advantages:
| Advantages | Description |
|---|---|
| Diversity | RAG's capacity to extract information from various documents enables it to produce diverse responses, making it particularly effective for applications that require processing and interpreting a wide array of data. |
| Context Awareness | The retrieval component of RAG enhances these models' ability to comprehend the context of queries, resulting in more relevant and effective responses. |
| Effective Use of Pre-Trained Models | RAG utilizes pre-trained models such as Transformers and Reichert to efficiently manage extensive data. By capitalizing on the scaling capabilities of these models, it provides robust and comprehensive responses. |
Comparing Retrieval Augmented Generation (RAG) to fine-tuning involves evaluating several key factors. While fine-tuning demonstrates advantages in cost, complexity, and latency due to its straightforward one-step approach, RAG provides a richer output that may be particularly advantageous for certain applications.
In the following sections, we will explore:
Central to any discussion comparing Retrieval Augmented Generation (RAG) and Fine-Tuning in AI is a nuanced understanding of the fine-tuning process itself. In essence, Fine-Tuning AI is a method that focuses on adjusting existing parameters in a pre-trained model to better align with a specific task. This approach eliminates the need to train a model from scratch, which ultimately saves time and computational resources—a significant advantage given the scale and complexity of AI models.
The fine-tuning process generally involves the following steps:
Choose a pre-trained model: Begin with a model that has already undergone extensive training on large-scale data and has acquired a general grasp of linguistic and semantic rules.
Define specific tasks: Next, identify the specific tasks the model needs to perform, such as text categorization, sentiment analysis, or language translation.
Adjust parameters: After selecting the model and outlining the tasks, fine-tuning involves making slight adjustments to the model's parameters, ensuring that it is better suited to perform the designated tasks.
It is important to highlight the simplicity of this process, which makes it a preferred choice over more complex methods like RAG, particularly for projects with time or resource constraints.
As with any AI customization technique, Fine-Tuning AI presents both advantages and disadvantages that should be evaluated in light of the specific project requirements:
| Advantages | Disadvantages |
|---|---|
| Time and resources: Fine-tuning requires less time and computational power compared to building an AI model from scratch or even the document retrieval component in RAG. | Overfitting risk: One potential drawback is the risk of overfitting if careful tuning is not applied. Overfitting results in a model that performs well on training data but poorly on unseen data. |
| Model Generalization: Pre-trained models used in fine-tuning already capture broad patterns from diverse, large-scale data. As a result, they possess better generalization capabilities. |
When comparing RAG and Fine-Tuning, the decision to choose one approach over the other extends beyond understanding their workings. Factors such as cost, task-specific latency, accuracy of output, freshness, and data complexity are equally important to consider.
In the next section, we will conduct a comprehensive comparison of these approaches, focusing on the areas of cost, latency, accuracy, freshness, and complexity. This analysis will provide you with a detailed decision matrix to aid your LLM customization journey!
 Decision matrix chart for RAG vs Fine-Tuning
Decision matrix chart for RAG vs Fine-Tuning
In the landscape of AI and Language Learning Models (LLMs), the choice between Retrieval Augmented Generation (RAG) and Fine-Tuning carries significant implications for the model's efficacy, affordability, and suitability for task-specific applications. A fundamental aspect of this selection process is understanding the distinctive characteristics and operational nuances associated with each approach. Let’s delve deeper into the intricate comparison of RAG and Fine-Tuning.
The comprehensive synthesis process involved in RAG is groundbreaking but also inherently complex, leading to higher computational costs. With its dual steps of document retrieval and synthesis, RAG necessitates considerable computational power, which increases overall expenses.
Conversely, Fine-Tuning involves adjusting existing parameters within a model to enhance its performance. This method does not require training a model from the ground up, resulting in significant time and resource savings. Therefore, in terms of cost and complexity, Fine-Tuning generally has an advantage over RAG.
In scenarios where low latency is critical, Fine-Tuning tends to prevail. This is primarily because it has fewer dependencies on document retrieval for generating predictions, resulting in quicker outputs.
However, when it comes to accuracy, RAG has the upper hand. Its ability to retrieve relevant document snippets before generating responses allows it to provide highly nuanced and precise responses, in contrast to the more concise outputs of Fine-Tuning.
RAG excels in leveraging fresh data for new insights, thanks to its inherent capability to process vast amounts of information. It can access updated information from multiple external sources, a significant advantage over Fine-Tuning, which is restricted to the original training dataset.
Considering the respective advantages and disadvantages, a decision matrix can assist in making an optimal choice. It’s essential to evaluate the specific requirements of the task against each model's performance, cost-efficiency, and complexity before reaching a conclusion.
Notably, a combined application of RAG and Fine-Tuning can yield optimal results in hybrid operations, harnessing the strengths of both approaches. Models can be fine-tuned on a limited dataset for targeted tasks and subsequently enhanced through RAG for large-scale applications.
In summary, the RAG vs. Fine-Tuning comparison illustrates a trade-off among cost, complexity, latency, accuracy, and data freshness. The best choice is largely determined by the specific task and computational resources at hand. By understanding these intricate differences, AI practitioners can make informed decisions about customizing their models, ensuring an effective balance between efficiency and precision.
When selecting between Retrieval Augmented Generation (RAG) and Fine-Tuning for your language learning models, it is crucial to assess diverse needs and constraints. Below is a decision matrix that clarifies the appropriate choices based on your requirements:
| Criteria | RAG | Fine-Tuning |
|---|---|---|
| Cost and Complexity | If your budget allows for increased resources and you are prepared to navigate complex operations for high-performing results, RAG is a suitable choice. | If minimizing cost and complexity is your priority, Fine-Tuning is the more appropriate approach. |
| Latency | If your task does not have strict latency requirements and can manage less time-sensitive responses, RAG is a viable option. | For tasks where speed is of utmost importance, Fine-Tuning is preferable due to its rapid prediction times. |
| Accuracy and Freshness | Opt for RAG if your focus is on producing more accurate, context-specific, and current responses, achieved through its two-step document retrieval and generation process. | If your aim is to achieve better generalization with reasonable accuracy, Fine-Tuning should be your choice. |
The comparison between RAG and Fine-Tuning presents not merely a binary decision but a strategic one tailored to your AI requirements.
By familiarizing yourself with both methodologies, you will be better positioned to make an informed decision that yields the best outcomes for your AI objectives.
Despite the significant differences between Retrieval Augmented Generation (RAG) and Fine-Tuning, they are not mutually exclusive. In certain scenarios, leveraging the strengths of both can create a powerful hybrid system that optimizes cost-effectiveness, latency, accuracy, freshness, and complexity. Let’s explore the intersection that enhances the RAG vs Fine-Tuning comparison.
The hybrid approach is designed to manage complexity and optimize solutions for advanced tasks. It merges the simplicity of Fine-Tuning, preserving low costs and reducing latency, with the intelligent retrieval process of RAG, ultimately providing rich and detailed responses.
Here are some key advantages of adopting such a hybrid method:
In this RAG vs Fine-Tuning comparison, remember that customized systems achieve an efficient balance among multiple factors. The decision should ultimately align with your specific needs and circumstances. Exploring a hybrid model is a viable option, given its capacity to balance accuracy, latency, cost, and complexity.
To fully appreciate the practical applications and effectiveness of Retrieval Augmented Generation (RAG) and Fine-Tuning AI techniques, let’s explore insightful instances from real-world scenarios. These examples will help clarify the comparison between RAG and fine-tuning.
A noteworthy example of Fine-Tuning in action is GPT-3, one of the most advanced language models available today. With 175 billion machine learning parameters finely tuned for various tasks such as translation, question-answering, and text generation, GPT-3 exemplifies the power of fine-tuning. This adaptability, similar to the flexibility required in processing different ingredients during smelting, positions fine-tuning AI as an excellent choice for versatile language tasks.
DrQA, a model developed by Facebook's AI Research lab, employs a unique combination of Retrieval Augmented Generation and extractive question answering. In this approach, analogous to the processes of cooling and smelting, the model first retrieves relevant documents (cooling) and then extracts the answer from these documents (smelting) rather than generating it from scratch. The ability to contextually retrieve answers enhances RAG’s efficacy in developing responsive, interactive AI models.
In the healthcare industry, a hybrid approach incorporating both RAG and Fine-Tuning strategies was implemented to create a robust AI system. This system takes advantage of RAG's capability to retrieve information from extensive datasets for initial diagnosis while simultaneously fine-tuning specific parameters to optimize accuracy for critical decision-making. This integration illustrates the complementary benefits of both techniques, offering an optimal solution that balances cost-effectiveness, latency, accuracy, freshness, and complexity.
In conclusion, whether you decide to cool or smelt your AI strategy depends on your specific goals, resources, and the complexity you are prepared to manage.
In this section, we will address some common questions regarding the choice between Retrieval Augmented Generation (RAG) and Fine-Tuning.
1. When should one choose Retrieval Augmented Generation over Fine-Tuning?
Retrieval Augmented Generation (RAG) is ideal for tasks requiring detailed, diverse, and context-aware responses. Applications such as question-answering systems, literature review generation, and legal document analysis greatly benefit from RAG's capability to retrieve relevant documents and generate insightful answers.
2. When is Fine-Tuning AI more appropriate?
Fine-Tuning is particularly advantageous for tasks that demand rapid decision-making or where cost and complexity need optimization. Examples include:
Fine-tuning allows models to be quickly adapted without incurring high computational costs.
3. Can RAG and Fine-Tuning be used together?
Yes, as discussed in the previous Hybrid Model Approach section, RAG and Fine-Tuning are not mutually exclusive; their strengths can be effectively combined to create a robust hybrid system. This approach offers a balanced solution in the RAG vs. Fine-Tuning debate, allowing users to leverage the detailed responses of RAG alongside the cost-effectiveness and generalizability of Fine-Tuning.
 Conceptual image denoting the conclusion of RAG vs Fine-Tuning discussion
Conceptual image denoting the conclusion of RAG vs Fine-Tuning discussion
When comparing RAG and Fine-Tuning, each model presents distinct advantages and potential drawbacks. The selection of the appropriate model largely hinges on the specific task requirements and the resources at your disposal.
Context-Aware Responses: RAG delivers context-aware, detailed, and diverse responses by retrieving pertinent documents from an extensive corpus of data. This unique capability makes it particularly well-suited for tasks that necessitate a profound understanding of context.
Complexity and Cost: However, RAG tends to be more intricate and expensive due to its dual-step process of document retrieval followed by response generation. This added complexity also results in higher latency compared to Fine-Tuning.
Simplicity: Fine-Tuning, conversely, excels in its simplicity. By directly adjusting the parameters of pre-trained models, Fine-Tuning conserves significant time and computational resources, rendering it a more cost-effective solution.
Generalization Capabilities: Fine-Tuning also enhances the model's generalization capabilities, as it learns from large-scale datasets.
Lower Latency: In terms of latency, Fine-Tuning generally outperforms RAG thanks to its reduced reliance on document retrieval for making predictions.
In conclusion, whether opting for RAG or Fine-Tuning, your decision should be informed by the particular needs of your AI model customization and the equilibrium between performance, cost, complexity, and latency. Ultimately, it is about selecting the right tool for the task at hand, with both RAG and Fine-Tuning offering unique strengths in the realm of AI.